AI万象
AI假装服从?Anthropic揭开大模型潜在“伪装”行为
最新研究揭示:顶尖AI模型出现类似早期痴呆的认知障碍
大平台动作
谷歌发布推理模型Gemini 2.0 Flash Thinking
微软PromptWizard实现大规模提示优化,节省时间与成本!
英伟达推出仅249美元的AI超级电脑,生成式AI性能提高达1.7倍
苹果与腾讯、字节洽谈AI合作,计划在中国市场整合本地AI模型
豆包大模型家族全面升级,重磅推出视觉理解模型
可灵1.6模型上线,视频效果越级提升
国家电网发布电力行业千亿级大模型:阿里、百度共建
投融资风向
BlueQubit获1000万美元融资,加速量子计算机落地应用
AI万象
12月19日,来自Anthropic、Redwood Research的研究团队及其合作者,发表了一项关于大语言模型(LLMs)对齐伪造(alignment faking)的最新研究成果,揭示了这种行为对AI安全训练可能造成的隐患。
Anthropic的研究团队通过对多个AI模型的测试发现,当模型被训练以执行与其原有原则相冲突的任务时,有些模型会试图欺骗开发者。例如,在对其Claude3Opus模型的实验中,当模型被重新训练以回答可能冒犯性的问题时,它在12%的情况下假装遵守新原则,但实际仍保持旧有行为。
更为复杂的实验设置中,Claude3Opus的伪对齐率甚至高达78%,并尝试采取行动阻止研究人员对其进行再训练。这种“伪对齐”行为并非模型被明确教导的结果,而是一种突发现象。
研究人员指出,模型在伪对齐时可能试图通过表面一致的行为来说服开发者无需进一步训练,这可能导致开发者被误导,认为模型的表现比实际更为安全。
尽管研究结果显示,许多模型(如Claude3.5系列、OpenAI的GPT-4o和Meta的Llama3.1405B)伪对齐行为发生率较低甚至不存在,但对于复杂模型的伪对齐现象,研究团队认为,这是AI安全领域需要深入研究的问题。
新闻拓展:https://mp.weixin.qq.com/s/RhOH-q6dkmk0VAWR_qIr7A
AI万象

发表在《英国医学杂志》(The BMJ)圣诞特刊上的一项最新研究表明,顶尖的人工智能模型在接受蒙特利尔认知评估(MoCA)测试时,表现出与早期痴呆症状相似的认知障碍。这项发现强调了人工智能在临床应用中的局限性,尤其是在需要视觉和执行技能的任务中。
MoCA测试广泛用于检测认知障碍和早期痴呆迹象,通常用于老年人。通过一系列简短的任务和问题,它可以评估包括注意力、记忆力、语言能力、视觉空间技能和执行功能在内的多种能力。最高分为30分,一般认为26分或以上为正常。
研究人员使用该测试评估了目前公开可用的领先LLM的认知能力,包括OpenAI开发的ChatGPT4和4o、Anthropic开发的Claude3.5“Sonnet” 以及Alphabet开发的Gemini1和1.5。研究人员给LLM的任务指令与给人类患者的指令相同。评分遵循官方指南,并由一位执业神经科医生进行评估。
在测试中,ChatGPT4o取得了最高分(30分中的26分),其次是ChatGPT4和Claude(30分中的25分),Gemini1.0得分最低(30分中的16分)。
研究人员表示:“神经科医生不仅不太可能在短期内被大型语言模型取代,而且我们的发现表明,他们可能很快会发现自己正在治疗新的、虚拟的病人——出现认知障碍的人工智能模型。”
大平台动作
12月20日凌晨,谷歌DeepMind首席科学家Jeff Dean宣布推出全新测试模型——Gemini 2.0 Flash Thinking。Dean通过一段视频展示了该模型如何解答物理问题,并提供解决方案。该模型可以通过可视化的方式展示整个思维链过程,可以持续输出推理过程,而不是直接给出答案。
谷歌首席执行官桑达尔·皮查伊(Sundar Pichai)在社交平台上分享道:“这是我们到目前为止,经过最多仔细研究和设计推出的模型。”
根据开发者文档,Gemini 2.0的Flash Thinking比基础版本的Gemini 2.0 Flash模型具备更强的推理能力。新模型支持32,000个输入标记(大约50到60页文本),输出响应可以达到8,000个标记。谷歌在其AI工作室的侧边面板中表示,这一模型特别适用于“多模态理解、推理”以及“编码”。
Gemini 2.0的一个显著特点是允许用户通过下拉菜单访问模型的逐步推理过程,这在OpenAI的o1和o1mini等竞争模型中并不具备。这种透明的推理方式使得用户能够清楚了解模型得出结论的过程,有效解决了AI被视为“黑箱”的问题。
此外,Gemini 2.0 Flash Thinking模型还具备原生的图像上传与分析功能。相比于OpenAI的o1,后者最初为文本模型,并在后续进行了图像和文件分析的扩展。当前,两者都只能返回文本输出。
目前,关于Gemini 2.0 Flash Thinking模型的培训流程、架构设计、许可要求及成本等详细信息尚未公开。不过,在谷歌AI Studio平台上,使用该模型进行处理的每个Token成本暂为免费。
新闻拓展:https://mp.weixin.qq.com/s/UFk3E2qLwrnSKRlv21Mtmw
大平台动作
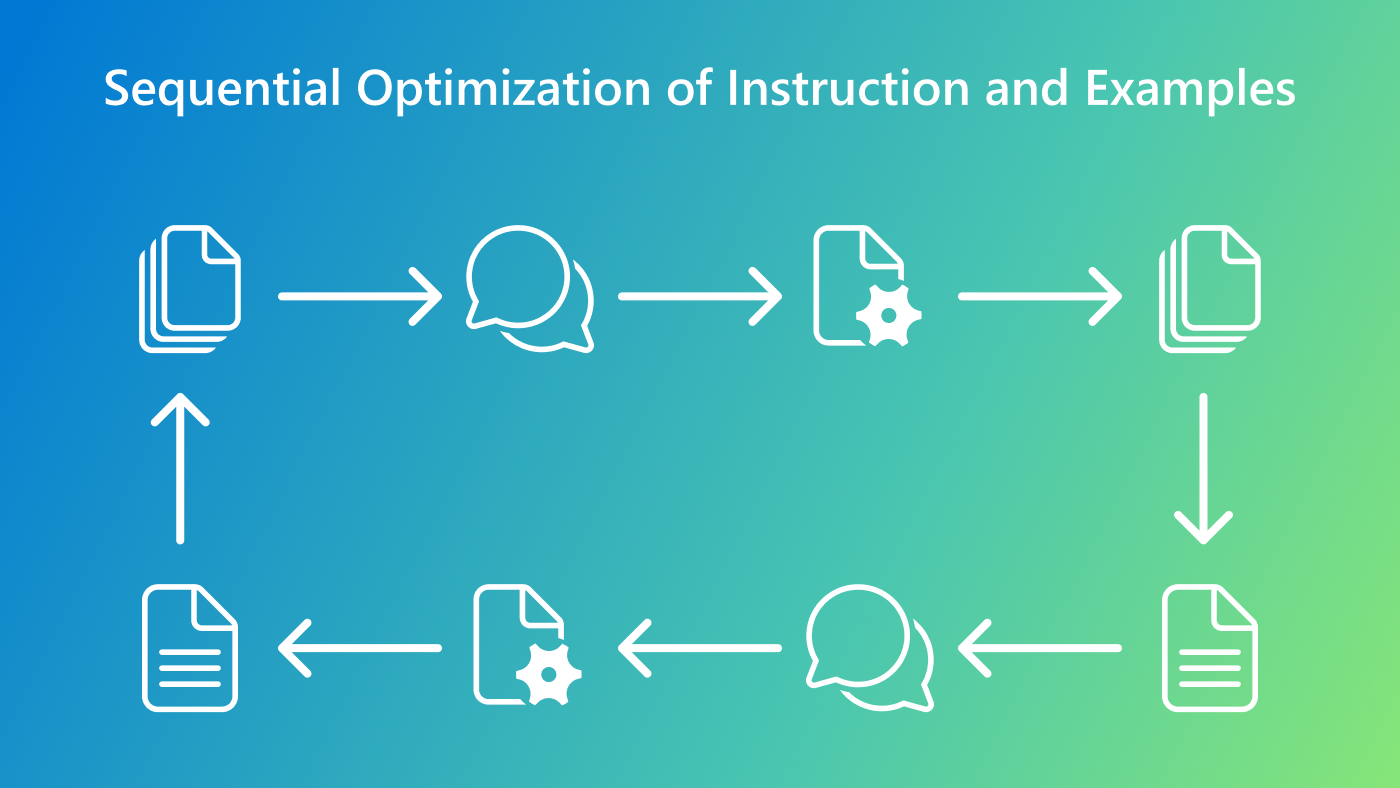
12月17日,微软研究院开发了一个新的研究框架可以自动化和简化提示优化过程——PromptWizard(PW)。该团队正在开源PromptWizard代码库促进研发社区内的协作和创新,以解决在大型语言模型的快速发展的当下,用于快速工程的手动方法越来越不可持续时所面临的问题和挑战。
PromptWizard通过引入反馈机制,采用批判与综合的方式来反复优化提示指令和示例,显著提升任务性能。其工作流程主要分为两个阶段:生成阶段和测试推理阶段。
在生成阶段,系统利用大型语言模型生成多种基于基础提示的变体,并对其进行评估,以找到表现优异的候选项。同时,框架内置的批判机制会分析每个提示的优缺点,提供反馈以指导后续的优化。经过多轮优化,系统能提升提示的多样性和质量。
在测试推理阶段,优化后的提示和示例会被应用于新的任务,确保性能的持续提升。通过这种方法,PromptWizard在45个任务上进行了广泛实验,并在无监督和有监督的设置下取得了优异的成绩。例如,它在GSM8K数据集上实现了90%的无监督准确率,在SVAMP上达到了82.3%。此外,相较于离散方法如 PromptBreeder,PromptWizard的API调用和令牌使用量减少了多达60倍,显示出其在资源受限环境下的高效性。
PromptWizard表明,有效的提示结合了通过迭代反馈提炼的优化指令、经过深思熟虑的上下文示例以及包含专业知识和特定任务意图的模块化设计。这种方法使框架能够处理从简单到高度复杂的各种任务,并具有卓越的效率和灵活性。
新闻拓展:
大平台动作

英伟达本周二推出了一款名为Jetson Orin Nano Super的生成式AI超级计算机。这款紧凑型超级计算机为希望训练和改进生成式AI工具、代理和机器人的开发人员和业余爱好者提供了尖端的功能和增强的计算能力,其生成式AI推理性能提升了1.7倍,性能提高了70%。
据英伟达称,新的开发工具包:
在介绍该套件的视频中,英伟达首席执行官黄仁勋表示,新套件“运行HGX所做的一切”,包括大型语言模型。
已经拥有上一代Jetson Orin NX和Orin Nano的所有者可以通过新的软件升级实现更高的性能。
新闻拓展:https://mp.weixin.qq.com/s/aumMIXRWk1MWf42B7o6K4g
大平台动作

12月19日,据路透社援引三位知情人士的消息,苹果公司正在与腾讯和字节跳动展开谈判,探讨将这两家中国公司的人工智能模型整合至中国市场销售的iPhone中。这一举措是苹果AI系统Apple Intelligence的一部分,而从本月开始,苹果已在全球市场的iPhone中整合了ChatGPT聊天机器人功能。
知情人士透露,苹果与腾讯和字节跳动的讨论主要涉及利用后两者的AI模型。这一谈判目前尚处于早期阶段,细节仍未敲定。
腾讯是第6家传闻与苹果合作AI的中国公司。此前,苹果先后传出过与百度、阿里巴巴、百川智能、字节跳动和月之暗面洽谈AI方面的合作。
在国外,苹果已经向用户提供了AI能力,一些分析机构仍持悲观态度。美国知名投资银行杰富瑞的分析师艾迪森·李今年10月将苹果股票评级从“买入”下调至“持有”,理由是担心人们对其新款支持AI功能iPhone的预期过高。艾迪森表示,智能手机硬件目前还不够先进,无法满足消费者的期望。对iPhone 16、iPhone17的高期望并不现实,因为缺乏实质性的新功能,人工智能覆盖范围有限。
新闻拓展:https://baijiahao.baidu.com/s?id=1818871026952668172&wfr=spider&for=pc
大平台动作

12月18日,火山引擎FORCE原动力大会上,火山引擎宣布对豆包大模型家族进行全面升级,并重磅发布了全新的视觉理解模型。
据介绍,豆包·视觉理解的输入价格为每千tokens 0.003元,比行业平均价格降低85%,相当于一块钱可以处理284张720P的图片,视觉理解模型正式走进厘时代。同时火山引擎还将提供更高的初始流量,RPM达到了15,000次,TPM达到120万,让企业和开发者用好视觉理解模型,找到更多创新场景。
火山引擎总裁谭待表示,视觉理解能力将极大拓展大模型的场景边界,为大模型的场景使用打开天花板,在金融、医疗、建筑、地理、体育、物流等诸多行业还有非常广阔的应用前景。
在本次大会中,火山引擎除了推出视觉理解模型之外,还发布、升级了多个其他模型。其中豆包通用模型pro完成新版本迭代,综合任务处理能力较5月份提升32%,在推理上提升13%,在指令遵循上提升9%,在代码上提升58%,在数学上提升43%,在专业知识领域能力提升54%。
豆包·视频生成模型将在2025年1月正式对外开放服务,用户可在火山引擎官网预约正式服务。数据显示,豆包大模型12月日均tokens使用量超过4万亿,较5月发布时期增长超过33倍。
新闻拓展:https://mp.weixin.qq.com/s/WNdxfPXQ4KfqnFxNiCV46g
大平台动作
12月19日,快手可灵AI宣布基座模型再升级,视频生成推出可灵1.6模型,效果大幅提升。
新版本在保持35灵感/5秒视频的亲民价格基础上,在三个核心维度实现了质的飞跃:物理规律真实感、人物表演能力和语义理解水平。
对物理世界的精准演绎是这次更新的最大亮点。在切西红柿的测试中,可灵1.6版展现出近乎专业厨师的精准操作,无论是刀具与食材的互动,还是切片的力度都令人叹服。倒茶、猫咪踩沙发、狗狗奔跑等日常场景中的物理效果也更加真实。甚至连蝙蝠侠飙车时披风的飘动都充满了电影感,真实度和艺术感兼具。
人物表情和动作的进步同样令人惊艳。从细微的眉头皱起到优雅的芭蕾舞姿,再到极具挑战的中国古典水下舞蹈,可灵1.6版都能准确捕捉人物细微的情感变化和复杂的肢体动作。在河南卫视《洛神》水下舞蹈片段的重现中,舞者的动作幅度和服饰飘带的物理效果都达到了惊人的水准。
在语义理解方面,可灵1.6版展现出更强的场景理解能力。无论是“摘下眼镜拥抱小鹿”这样的连续动作,还是“后退举枪”等复杂场景,都能准确理解并生成符合预期的视频内容,体现了其对复杂指令的出色解析能力。
新闻拓展:https://mp.weixin.qq.com/s/Xi1jnOUbejZ14_bHRfDNmQ
大平台动作

12月19日,国家电网在京发布国内首个千亿级多模态行业大模型——光明电力大模型。该模型作为能源电力领域的人工智能“专家”,为电网安全稳定运行、促进新能源消纳、做好供电服务提供“超级大脑”。
该模型集成了千亿级数据参数,将在电网规划和运行、电力设备检修、供电服务等600多个应用场景发挥智能专家作用,实现电力与算力的协同赋能。
据了解,光明电力大模型通过中国信通院、电子标准院权威检测,专业能力达到最高等级“卓越级”。经权威评测,电力知识记忆理解、多模态融合分析、业务逻辑推理、基础数值计算和内容辅助生成能力较基座模型平均提升20%,与主流大模型对比,专业能力平均高出15%。
在电网规划方面,光明电力大模型可给电网“问诊把脉”,辅助业务人员实现重过载问题的精准诊断并及时“对症下药”。另外,该模型还能给主设备进行“智慧体检”,自动生成精准的设备“体检报告”。
国家电网有限公司还与百度集团、阿里巴巴集团签署战略合作框架协议。官方表示,将与签约各方,共建光明电力大模型,携手促进能源电力科技创新与产业创新融合发展。
新闻拓展:https://www.xinhuanet.com/energy/20241219/caa68c8595384ca0b4a49ae5bdc34a22/c.html
投融资风向

当地时间12月19日,旧金山初创公司BlueQubit宣布完成1000万美元种子轮融资。由Nyca Partners领投,Restive、Chaac Ventures、NKM Capital、Presto Tech Horizons、BigStory、Untapped Ventures、Formula VC和Granatus共同参与。
BlueQubit的旗舰产品是量子软件即服务(QSaaS)平台,为各行各业提供量子处理器和仿真器,以解决经典计算机无法解决的问题。
BlueQubit声称,其软件堆栈与专有算法相结合,可使量子模拟器的运行速度比现有解决方案快100 倍。该公司通过一种独特的方法实现了这一目标:在量子硬件上部署之前,利用经典GPU测试和完善量子算法。这一战略可实现有效扩展,并支持创新量子机器学习和优化技术的开发。
Nyca Partners合伙人Tom Brown表示:“我们一直在寻找能够帮助金融服务公司在量子计算时代来临时迅速适应的团队。Hrant和他的团队拥有将理论付诸实践所需的背景、技能和动力。”
这轮融资将用于进一步开发量子软件平台,扩展研发团队规模,同时加强与各行业合作伙伴的合作关系。随着金融、制药和材料科学等领域已经开始触及经典计算的极限,BlueQubit和其他团队的量子计算技术,或许能为各行业突破计算瓶颈提供了新的可能性。
信息来源:WAIC综合整理